



The Vidar embodied AI model from ShengShu uses simulated worlds instead of physical training data. Source: Adobe Stock, Vectorhub by ice
ShengShu Technology Co. yesterday launched its multi-view physical AI training model, Vidar — which stands for for “video diffusion for action reasoning.” Using Vidu’s capabilities in semantic and video understanding, Vidar uses a limited set of physical data to simulate a robot’s decision-making in real-world environments, said the company.
“Vidar offers a radically different approach to training embodied AI models,” stated ShengShu Technology. “Just as Tesla focuses on vision-based training and Waymo leans into lidar, the industry is exploring divergent paths to physical AI.”
Founded in March 2023, ShengShu Technology specializes in the development of multimodal large language models (LLMs). The Beijing-based company said it delivers mobility-as-a-service (MaaS) and software-as-a-service (SaaS) products for smarter, faster, and more scalable content creation.
With its flagship video-generation platform Vidu, ShengShu said it has reached users in more than 200 countries and regions around the world, spanning fields including interactive entertainment, advertising, film, animation, cultural tourism, and more.
Vidar simulated training to accelerate robot development
“While some companies train physical AI by embedding models into real-world robots and collecting data through the physical interactions that their robots encounter, it’s a method that’s costly, hardware-dependent, and difficult to scale,” said ShengShu Technology. “Others rely on purely simulated training, but this often lacks the variability and edge-case data needed for real-world deployment.”
Vidar takes a different approach, the company claimed. It combines limited physical training data with generative video to make predictions and generate new hypothetical scenarios, creating a multi-view simulation featuring lifelike training environments, all within a virtual space. This allows for more robust, scalable training without the time, cost, or limitations of physical-world data collection, explained ShengShu.
Built on top of the Vidu generative video model, Vidar can perform dual-arm manipulation tasks with multi-view video prediction and even respond to natural-language voice commands after fine-tuning. The model effectively serves as a digital brain for real-world action, said the company.
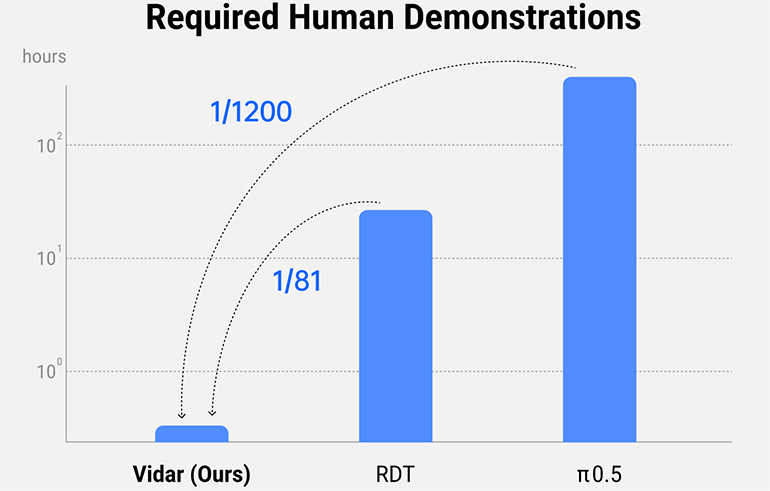
Using Vidu’s generative video engine, Vidar generates large-scale simulations to reduce dependency on physical data, while maintaining the complexity and richness needed to train real-world-capable AI agents. ShengShu said Vidar can extrapolate a generalized series of robotic actions and tasks from only 20 minutes of training data. The company asserted that is between 1/80 and 1/1,200 of the data needed to train industry-leading models including RDT and π0.5.
ShengShu said Vidar’s core innovation lies in its modular two-stage learning architecture. Unlike traditional methods that merge perception and control, Vidar decouples them into two distinct stages for greater flexibility and scalability.
In the upstream stage, large-scale general video data and moderate-scale embodied video data are used to train Vidu’s model for perceptual understanding.
In the second downstream stage, a task-agnostic model called AnyPos turns that visual understanding into actionable motor commands for robots. This separation makes it significantly easier and faster to train and deploy AI across different types of robots, while lowering costs and increasing scalability.

Vidar is designed to reduce the amount of training data needed to train AI models. Source: ShengShu Technology.
Vidar a framework for scalable embodied intelligence
Vidar follows a scalable training framework inspired by language and image foundation models of the past decade of AI breakthroughs. ShengShu said its three-tiered data pyramid, spanning large-scale generic video, embodied video data, and robot-specific examples, makes for a more flexible system, reducing traditional data bottleneck.
Built on the U-ViT architecture, which explores the fusion of diffusion models and transformer architectures for a wide assortment of multimodal generation tasks, Vidar harnesses long-term temporal modeling and multi-angle video consistency to power physically grounded decision-making.
This design supports rapid transfer from simulation to real-world deployment, which ShengShu said is critical for robotics in dynamic environments. It also minimizes engineering complexity, according to the company,
ShengShu said Vidar can facilitate robotics adoption across multiple sectors. From home assistants and eldercare to smart manufacturing and medical robotics, the model enables fast adaptation to new environments and multi-task scenarios, all with minimal data, it added.
Vidar creates an AI-native path for robotics development that is efficient, scalable, and cost-effective, ShengShu claimed. By transforming general video into actionable robotic intelligence, the company said its model can bridge the gap between visual understanding and embodied agency.


Vidar has a modular learning architecture. Source: ShengShu Technology
ShengShu marks milestones in multimodal AI
Vidar builds on the rapid momentum of the Vidu video foundation model, said ShengShu. The company listed statistics since its debut:
- Vidu reached 1 million users within one month
- Surpassed 10 million users in just three months
- Generated over 100 million videos by Month 4
- Reference-to-video generation exceeded 100 million by Month 8
- Total generated videos now top 300 million
ShengShu continues to expand the frontiers of multimodal AI, Vidar represents the next frontier—bringing generalization, generativity, and embodiment into one unified system.
Editor’s note: RoboBusiness 2025, which will be on Oct. 15 and 16 in Santa Clara, Calif., will include tracks on physical AI and humanoid robots. Registration is now open.

