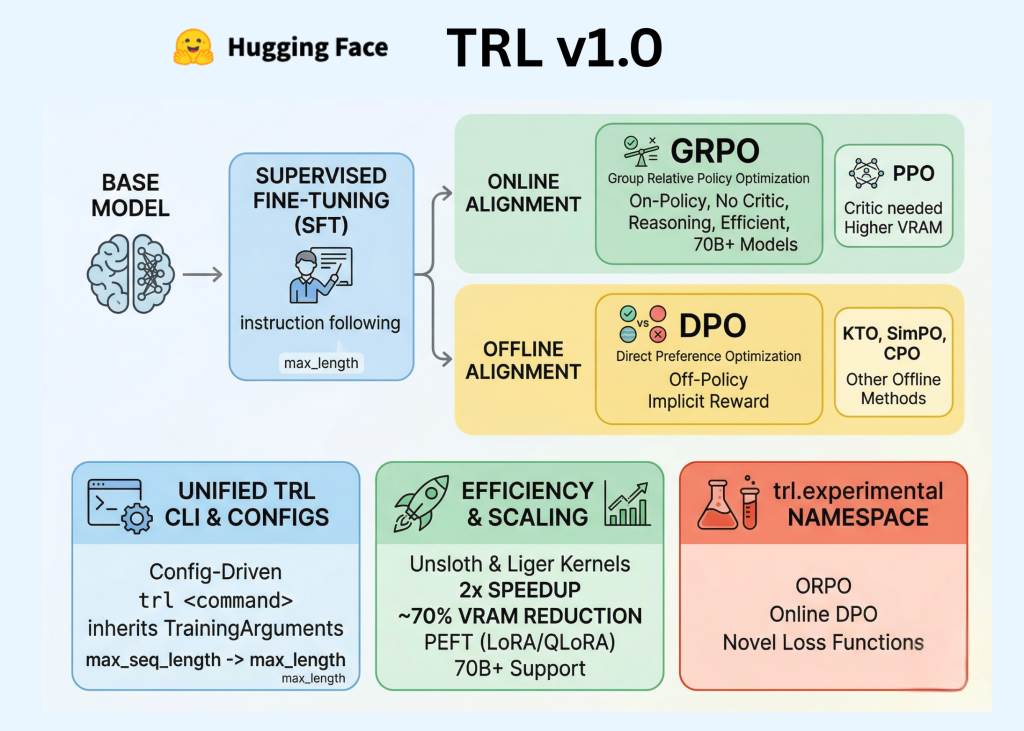
Hugging Face has officially released TRL (Transformer Reinforcement Learning) v1.0, marking a pivotal transition for the library from a research-oriented repository to a stable, production-ready framework. For AI professionals and developers, this release codifies the Post-Training pipeline—the essential sequence of Supervised Fine-Tuning (SFT), Reward Modeling, and Alignment—into a unified, standardized API.
In the early stages of the LLM boom, post-training was often treated as an experimental ‘dark art.’ TRL v1.0 aims to change that by providing a consistent developer experience built on three core pillars: a dedicated Command Line Interface (CLI), a unified Configuration system, and an expanded suite of alignment algorithms including DPO, GRPO, and KTO.
The Unified Post-Training Stack
Post-training is the phase where a pre-trained base model is refined to follow instructions, adopt a specific tone, or exhibit complex reasoning capabilities. TRL v1.0 organizes this process into distinct, interoperable stages:
- Supervised Fine-Tuning (SFT): The foundational step where the model is trained on high-quality instruction-following data to adapt its pre-trained knowledge to a conversational format.
- Reward Modeling: The process of training a separate model to predict human preferences, which acts as a ‘judge’ to score different model responses.
- Alignment (Reinforcement Learning): The final refinement where the model is optimized to maximize preference scores. This is achieved either through “online” methods that generate text during training or “offline” methods that learn from static preference datasets.
Standardizing the Developer Experience: The TRL CLI
One of the most significant updates for software engineers is the introduction of a robust TRL CLI. Previously, engineers were required to write extensive boilerplate code and custom training loops for every experiment. TRL v1.0 introduces a config-driven approach that utilizes YAML files or direct command-line arguments to manage the training lifecycle.
The trl Command
The CLI provides standardized entry points for the primary training stages. For instance, initiating an SFT run can now be executed via a single command:
trl sft --model_name_or_path meta-llama/Llama-3.1-8B --dataset_name openbmb/UltraInteract --output_dir ./sft_resultsThis interface is integrated with Hugging Face Accelerate, which allows the same command to scale across diverse hardware configurations. Whether running on a single local GPU or a multi-node cluster utilizing Fully Sharded Data Parallel (FSDP) or DeepSpeed, the CLI manages the underlying distribution logic.
TRLConfig and TrainingArguments
Technical parity with the core transformers library is a cornerstone of this release. Each trainer now features a corresponding configuration class—such as SFTConfig, DPOConfig, or GRPOConfig—which inherits directly from transformers.TrainingArguments.
Alignment Algorithms: Choosing the Right Objective
TRL v1.0 consolidates several reinforcement learning methods, categorizing them based on their data requirements and computational overhead.
| Algorithm | Type | Technical Characteristic |
| PPO | Online | Requires Policy, Reference, Reward, and Value (Critic) models. Highest VRAM footprint. |
| DPO | Offline | Learns from preference pairs (chosen vs. rejected) without a separate Reward model. |
| GRPO | Online | An on-policy method that removes the Value (Critic) model by using group-relative rewards. |
| KTO | Offline | Learns from binary “thumbs up/down” signals instead of paired preferences. |
| ORPO (Exp.) | Experimental | A one-step method that merges SFT and alignment using an odds-ratio loss. |
Efficiency and Performance Scaling
To accommodate models with billions of parameters on consumer or mid-tier enterprise hardware, TRL v1.0 integrates several efficiency-focused technologies:
- PEFT (Parameter-Efficient Fine-Tuning): Native support for LoRA and QLoRA enables fine-tuning by updating a small fraction of the model’s weights, drastically reducing memory requirements.
- Unsloth Integration: TRL v1.0 leverages specialized kernels from the Unsloth library. For SFT and DPO workflows, this integration can result in a 2x increase in training speed and up to a 70% reduction in memory usage compared to standard implementations.
- Data Packing: The
SFTTrainersupports constant-length packing. This technique concatenates multiple short sequences into a single fixed-length block (e.g., 2048 tokens), ensuring that nearly every token processed contributes to the gradient update and minimizing computation spent on padding.
The trl.experimental Namespace
Hugging Face team has introduced the trl.experimental namespace to separate production-stable tools from rapidly evolving research. This allows the core library to remain backward-compatible while still hosting cutting-edge developments.
Features currently in the experimental track include:
- ORPO (Odds Ratio Preference Optimization): An emerging method that attempts to skip the SFT phase by applying alignment directly to the base model.
- Online DPO Trainers: Variants of DPO that incorporate real-time generation.
- Novel Loss Functions: Experimental objectives that target specific model behaviors, such as reducing verbosity or improving mathematical reasoning.
Key Takeaways
- TRL v1.0 standardizes LLM post-training with a unified CLI, config system, and trainer workflow.
- The release separates a stable core from experimental methods such as ORPO and KTO.
- GRPO reduces RL training overhead by removing the separate critic model used in PPO.
- TRL integrates PEFT, data packing, and Unsloth to improve training efficiency and memory usage.
- The library makes SFT, reward modeling, and alignment more reproducible for engineering teams.
Check out the Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.